多分类问题
N分类问题(N>2)最朴素的解决方案是拆分为N个二分类问题。但这样做的问题是不同类别间应该是互斥的(或者说相互抑制),直接拆分的话可能每个类别的概率都很高(或者加起来不等于1)。
Softmax Layer
假定$z^l\in\mathbb{R}^K$ 是最后一个线性层的输出,softmax layer的形式为:
$P(y=i)=\frac{e^{z_i}}{\sum_{j=0}^{K-1}e^{z_j}},i\in\{0,\dots,K-1\}$Softmax layer的好处是可以把最后一层的输出归一化为每一类[0,1]的概率,且概率和为1
注:之前的朴素二分类问题,因为最后一层以sigmoid函数结尾,只有一个[0,1]的输出,本身符合概率定义,所以不需要用softmax。损失的计算直接用二类交叉熵就行了。
Softmax的损失函数
Softmax层后接的损失函数仍然可以用交叉熵, 如图(NLLLoss, negative log likelihood loss):
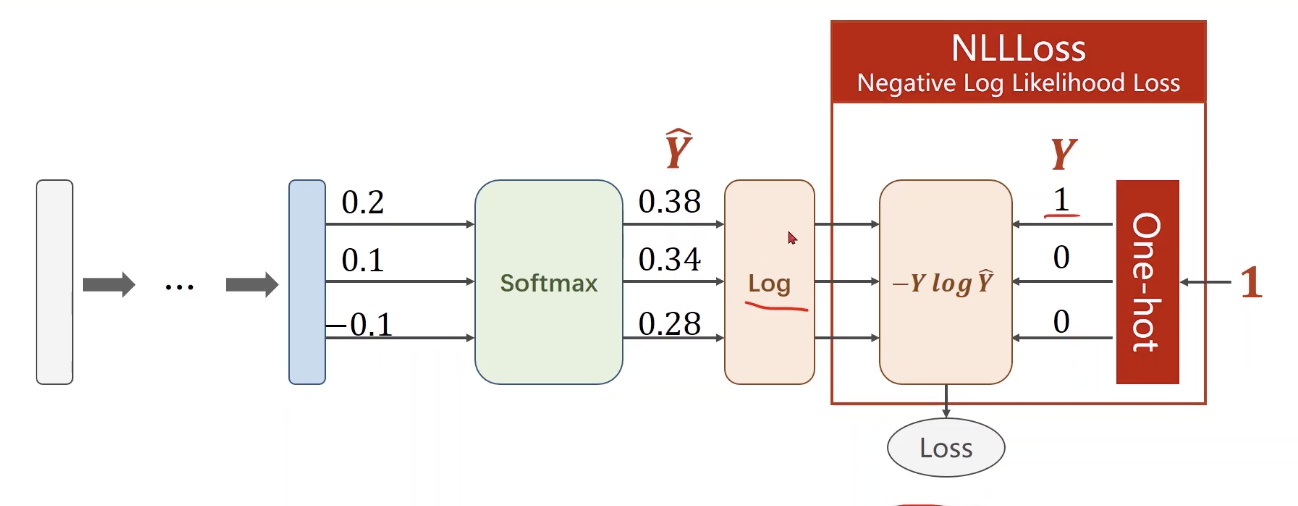
具体公式为$Loss(\hat{Y},Y)=-Y\log\hat{Y}$,上图中最右侧的1为label,经过一个binarizer转化为one-hot表示,即一个维数为label类别总数的01向量,其中只有一维为1。这个向量作为$Y$,与softmax层的预测值$\hat{Y}$求交叉熵。
补充一下这里采用的交叉熵公式:
$-\sum_{c=1}^My_{o,c}\log(p_{o,c})$- M - number of classes (dog, cat, fish)
- log - the natural log
- y - binary indicator (0 or 1) if class label $c$ is the correct classification for observation $o$
- p - predicted probability observation $o$ is of class $c$
所以这里的交叉熵结果其实就是正确的那个类别预测概率(正确类别的softmax输出值)取log的负值,其它类别的概率都乘了0。
实现的基本原理:
1 | import numpy as np |
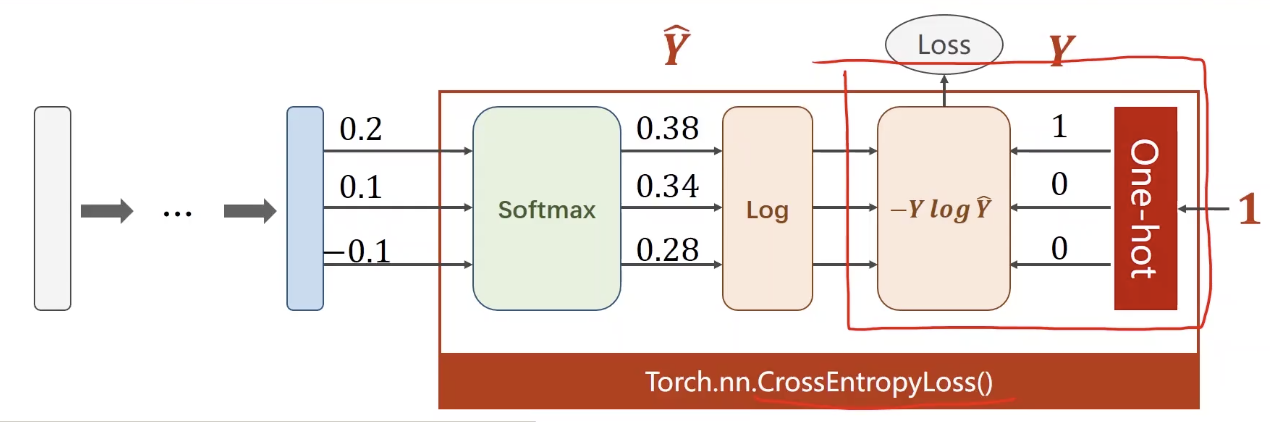
采用torch中提供的CrossEntropyLoss的实现方式:
1 | import torch |
一个更具体的例子:
1 | import torch |
补充:PyTorch中CrossEntropyLoss和NLLLoss的关系:
CrossEntropyLoss<==>LogSoftmax+NLLLoss
实例:MNIST数据集训练
Prepare dataset
Dataset and Dataloader
Design model using Class
- Inherit from nn.Module
Construct loss and optimizer
Training cycle + Test
- forward, backward, update
1 | import torch |
课程来源:《PyTorch深度学习实践》完结合集